ELISA数据处理
用ELISA数据进行的结果计算以及有关统计测定验证的推荐指导原则。
计算结果
ELISA样品应采用两个重复或三个重复测定。这样能为结果的统计验证提供足够的数据。目前已有许多计算机程序能够以这样的方式处理ELISA结果。
计算每组重复测定标准品和重复测定样品的平均吸光度值。重复测定的各值相对于平均值的偏差应在20%范围内。
标准曲线
以平均吸光度为X轴、靶蛋白浓度为Y轴绘制靶蛋白标准曲线。通过图中各点绘制最佳拟合曲线(建议使用相关计算机程序来完成)。
我们推荐在每个酶标板上都加上标准品,保证每个酶标板都能做出标准曲线。
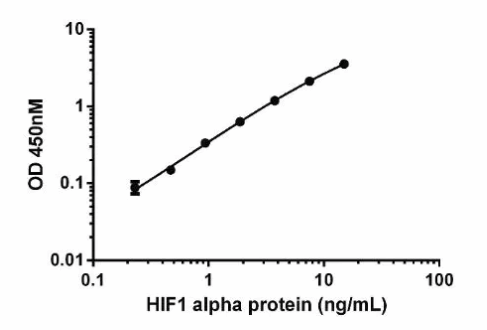
典型的标准曲线如下图所示,该数据得自人HIF1 α SimpleStep ELISATM试剂盒(ab171577)。图上的每个点代表三次平行滴定的平均值。
我们推荐用已知浓度的样品作为阳性对照。为获得有效而准确的结果,阳性对照样品的浓度应位于标准曲线的线性区域内
样品中靶蛋白的浓度
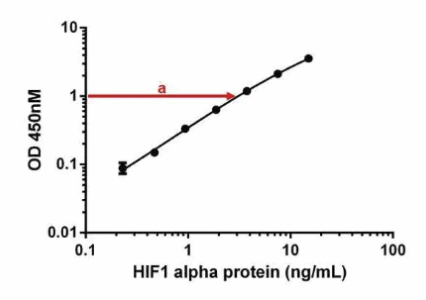
要确定每个样品中的靶蛋白浓度,首先需要得到样品的平均吸光度值。然后从标准曲线图Y轴上的该值处,绘制一条与标准曲线相交的水平线。
例如,如果吸光度读数为1,则从 Y 轴上的该点绘制这条直线(a):
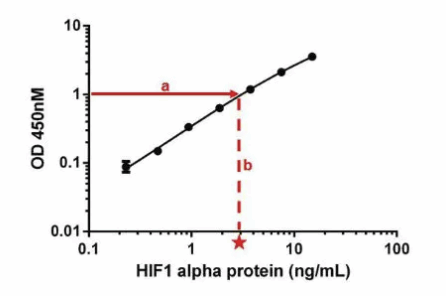
在交点处,绘制一条垂直于X轴的直线,读取相应的浓度(b)。
吸光度值落在标准曲线范围外的样品
要获得准确的结果,应先稀释这些样品,再继续进行ELISA染色。若使用这类样品,在分析结果时须将由标准曲线获得的浓度乘以稀释倍数。
计算变异系数
变异系数(CV)为标准差σ与平均数μ的比值:
Cv= σ
μ
这一数据即为方差占平均数的百分比,代表了结果的不一致性和不准确性。方差越大表示结果的一致性和准确性越差。有些计算机程序能够计算ELISA结果的CV值。
CV较大可由以下原因引起:
移液不准确;在使用前确保枪头在移液器上套牢,确保吸取正确的液体量
试剂溅入其他孔中
样本或试剂受细菌或真菌污染
试剂间交叉污染
酶标板各处温度不一致;确保酶标板在远离气流的恒温环境中孵育
部分孔干透;确保酶标板在孵育过程中始终处于被封盖状态
加标回收率
加标回收率可判断的样品成分对抗体抗原检测的影响。例如,组织培养物上清液中所含的大量蛋白质可能会阻碍抗体结合,提高信噪比,从而导致得到的浓度低于实际值。
将已知浓度的蛋白质加至样品基质和标准稀释剂中。用同样的测定方法对加标蛋白质进行定量,并将样品基质和标准稀释剂的结果进行对比。
如果二者结果相同,那么样品基质可视为适用于测定程序。如果回收率不同,则说明样品基质中的组分会干扰分析物检测。
如果加标回收实验说明样品基质对结果有影响该怎么办?
我们推荐在样品基质中稀释标准品以得到标准曲线。样品基质对结果的一切影响也存在于标准品中,因此标准曲线和样品间的比较更为准确。我们许多的ELISA试剂盒中包含专为此提供的标准血清稀释剂。
另一解决方法则是改变样品基质。例如,如果使用未稀释的生物样品,可在标准稀释剂中稀释样品。然而使用此方案,您需要确保在分析结果时将稀释倍数考虑在内,并且浓度保持在标准曲线的线性区域内。